Kafka as a Single Source of Truth


Apache Kafka is the most popular distributed event streaming platform mostly used for transforming and moving the data between different systems. We can find plenty of use cases for data pipelines, mission-critical event driven systems, data integrations and transformations, but not many platforms use Kafka as a single database. That is why we decided to share our decisions why we choose Kafka to be the single source of truth for Airy, as well as the experiences that we had along our journey.
Airy requirements & concepts
At the start it is fair that we first we exlain our platform requirements and development principles. Four years ago we were fortunate to start working on a completely new streaming platform, determined to transform conversational experiences. As we wanted to connect conversational, business and machine leraning systems in real-time, we had few requirements in place for our platform:
- It should be an event driven system
- There needs to be a microservice architecture & service independence
- The data should be in order and easily re-processable
- There should be a single data storage for all the event data
- We should be able to add business logic in the stream and in real-time
- The platform should be able to scale
Naturaly the choice for the core of the system came to Apache Kafka, as it fits all of these requirements. For adding the business logic in the stream we choose to rely on the Kafka Streams library for building our components. And as an infrastructure where everything should run we opted for Kubernetes as it is a perfect environment for deploying microservices, that are able to scale both horizontally and vertically, with lots of other enterprise-grade features that are independent of any cloud provider.

Single source of truth
As we needed data from different places at the beginning we were really determined to have a single source of truth and avoid having data in different places, not being able to read and process it in a standardized way. But what is all that data that we need to store in a platform like Airy? First is all the conversational data which means all the messages and events that are ingested from the verious conversational platforms such as Facebook, Google, Instagram, Twilio, SMS and so on. In order to design automations and enrich the conversations we need to also fetch data from various business systems, for example Zendesk, Salesforce, purchase data or other customer databases.
The same datastore should also hold configuration settings about the connectors and preferences for the users using the platform. It should be able to also store structured contact data about the contacts that are being ingested and aggregated over different channels.
Last but not least the same data store should hold all the logs and events that are generated by the applications, including metrics, monitoring data and telemetry.
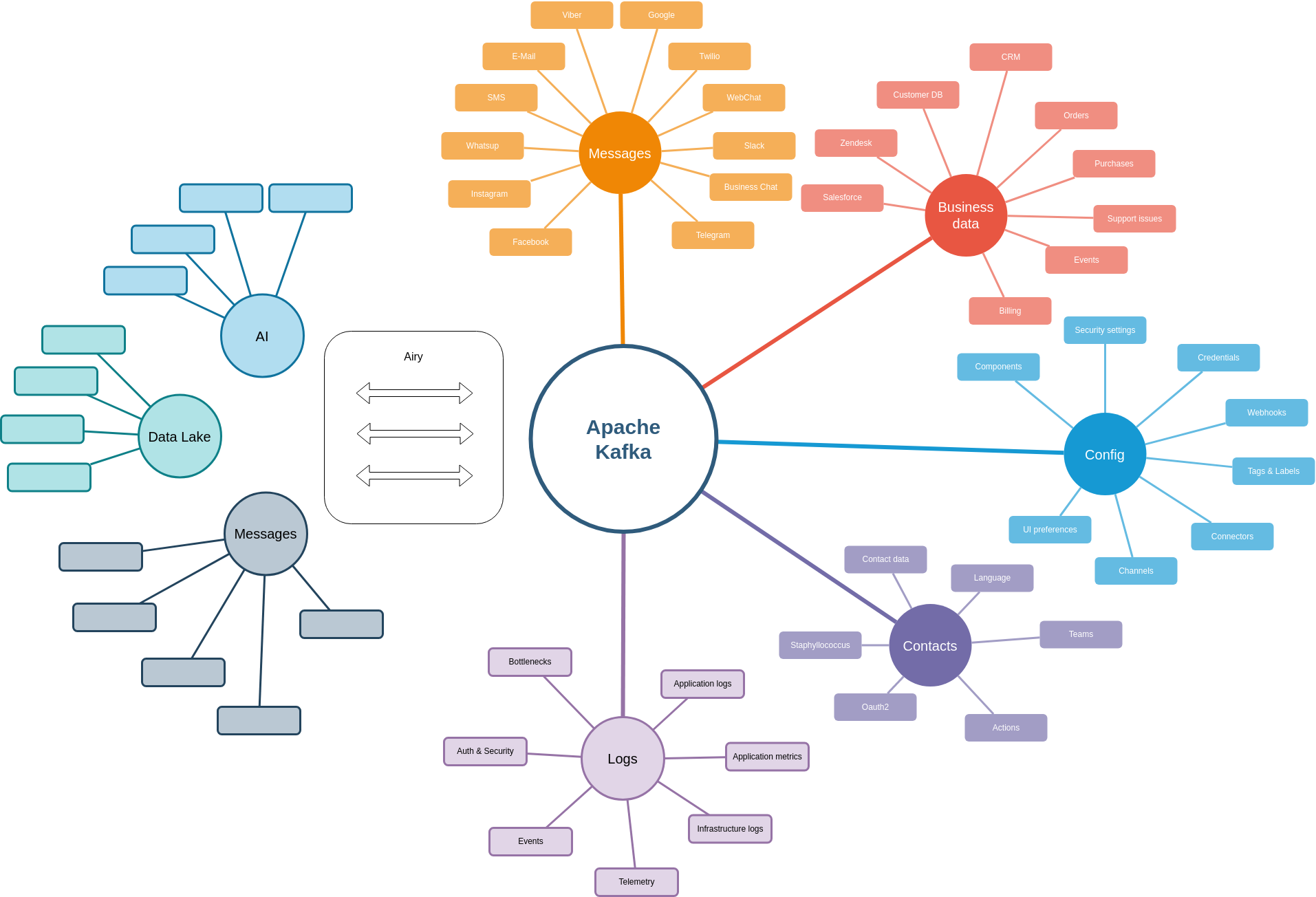
One would legimitely ask: But is Kafka the appropriate data store for all that? We figured out: Yes! We should have all the data on top of which we want to build real-time business logic in Kafka. This way we are flexible with the variety of features and applications we can add on top, while using a standard way to access and process the data. In a way we are able to transparently treat all the data the same, regardless of where it comes from and what should it trigger.
Even though there is an option to combine Kafka with other relational and non-relational databases, that way we would have the same information in multiple places, would be hard to determine which is the source of truth and the unification of the development process would become harder. And to be honest Kafka Streams helped our decision because it is a great library to have stateless and stateful operations on top of the data in Kafka and in real-time.
So, to wrap it up, all data lives in Kafka. Everything goes into the stream and that is where every app reads from to built its own version of reality, a very important principle for having complete service independence. So the data can also be seen as a strongly typed (via Avro) data pipeline. Let's see now how this pipeline powers all the apps and services.
Microservice design & architecture
Airy is built of Kafka Streaming Apps called components. They can be of three types:
- Transformers - Consume data from topics, perform stateful and stateless transformations and write to other topics.
- Services - Consume data from topics, perform transformations, hold the state in internal topics and expose endpoints.
- Connectors - Ingest data from external systems into Kafka and send data from Kafka to external systems.
We choose to build our own Airy connectors and not build on top of kafka-connect because we had the need for:
- Sending and receiving data within the same connector (not to have separate
sinkandsourceconnectors). - Add business logic inside the connector and not simply get the data from one place to another.
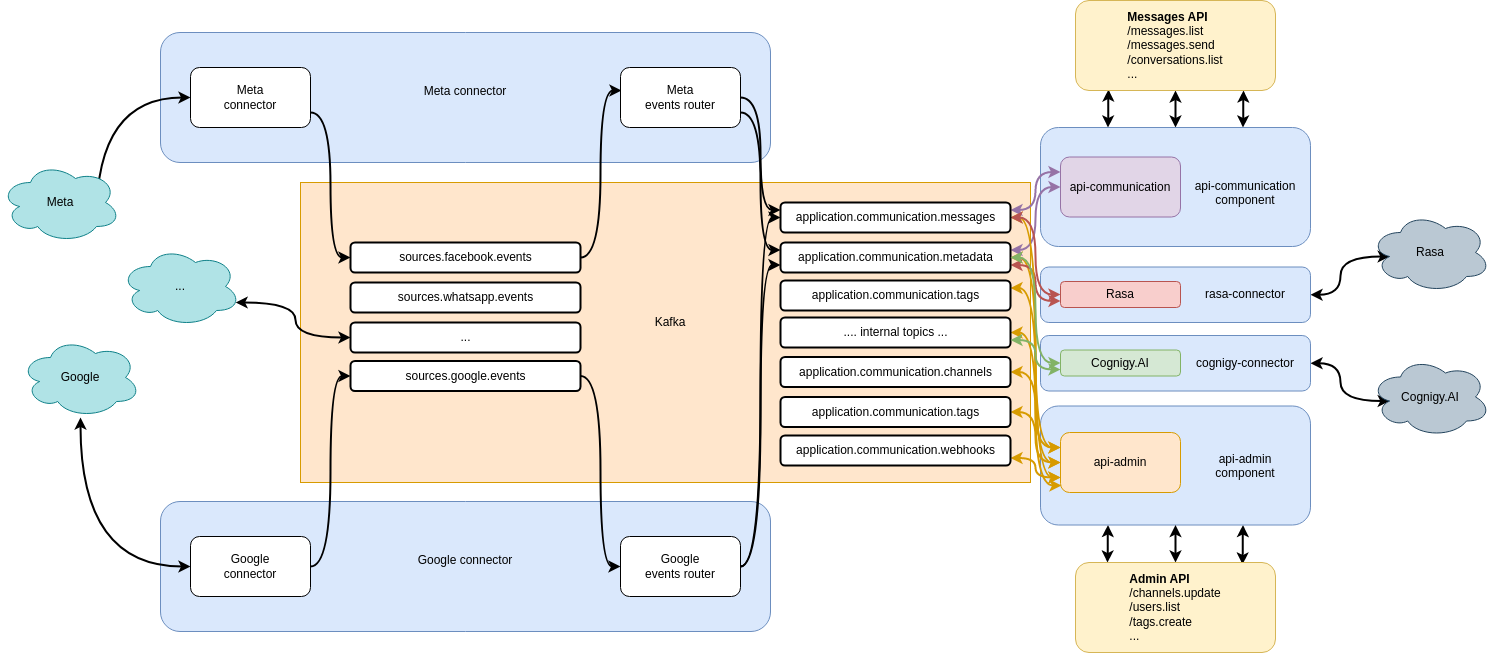
For example, as illustrated on the image above, a message is injected into Kafka through a microservice in a connector. Afterwards another microservice in the same connector reads this data, transforms it and writes it into another topic. This event is a trigger for other components to do something with this data. Here the true power of Kafka comes into place, as we can have components with higher priority to which we dedicate more resources and also components with a lower priority, but who read the same data on best-efforts workloads.
Every microservice has its own topology which is a representation of the relations between the data that is read and the operations performed on this data. As mentioned above, these operations can be stateful operations such as joins and aggregations and the result from them is stored into internal topics. When the schema for the resulting topics needs to change or we need to change the topology, these Kafka Streaming Apps need to be reset and the data in these internal topics will be deleted. Then the microservice starts to re-process the data again, from beginning, latest or from a specific offset.
One important aspect of our HTTP endpoints of services is that they are built on top of a very useful feature of Kafka Streams called interactive queries. As the stateful operation on multiple topics is performed and the state is stored into internal topics, interactive queries allow this structured data to be exposed to the outside world.
Learnings
Of course everything looks great on the design whiteboard, but unfortunateyl real-time and scalable event-driven platforms don't run on whiteboards.
Here are some of the obstacles that we had along our journey and some of the learnings that we made.
Learning 1: Endpoint performance
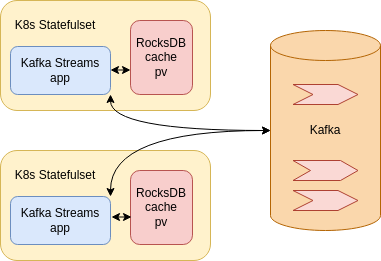
The services behind the endpoints need to be fast. As explained before, this data is loaded from the internal topics and that can take time for larger data sets. Fortunately the Interactive queries support local and remote state stores, which means that a local state is kept on the workload in a form a cached version of the data created by the particular topology. To increase the performance, which is particularly important when the microservices start, it is useful to have these workloads as StatefulSets in Kubernetes, provisioning a stateful volume where there is a cached version of the data from the internal topics. As Kafka Streams uses a default RocksDB as a default storage to maintain local state, having this storage persistent will help with improving the endpoint performance.
Learning 2: Changing the schema
The schema holds the structure of the data and when working with Kafka it can be stored in a separate service called the Schema Registry. Changing the schema of the data is inevitable over time. But as the data with the specific schema is already in the internal topics of the Kafka Streams Apps and in the RocksDB cache, thich can be a painful process. If we want to change the schema of a microservice, usually the procedure to do this is:
- Scale down the StatefulSets
- Reset the kafka-streaming-app
- Delete the persistent storage
- Scale up the workloads
- Wait for the reprocessing
But going through this approach will mean that there would be a downtime. And depending on the amount of the data and the time it takes to reprocess it it can be quite significant. To mitigate the downtime we can leverage the service or loadBalancer feature of Kubernetes and deploy a new app that can introduce the new schema while the first app is still working.
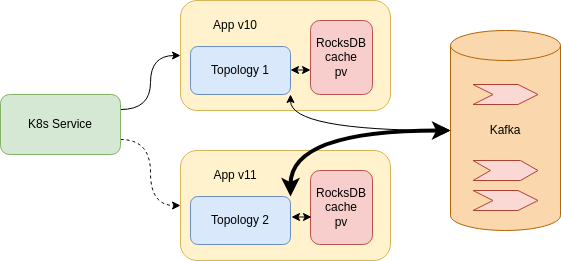
The new microservice however needs to have a different name for the consumer group in Kafka because that is how Kafka distinguishes different consumers.
Even through now there is no preasure with reprocessing the data for App v11 as App v10 is still running, there might be a case where we need to fix a bug in the existing app. In this case, it is important that the second app consumes all the needed topics and becomes ready to serve the clients faster. We can achieve this if we use workloads with more CPU and memory only during the period while the data is reprocessed and the Kafka Streams App gets in a RUNNING state. One way to achieve this if creating very powerful compute nodes in the cloud (we call them boost-k8s-nodes) on the fly and joining them to the Kubernetes cluster. Then we need to set more resources and label the App v11 workloads so that they get scheduled on the new nodes. Once the reprocessing of the messages is done, we can scale down the resources for the new app and deploy them of regulat nodes. Important not to forget ot destroy the boost-k8s-nodes because they can lead to large costs.
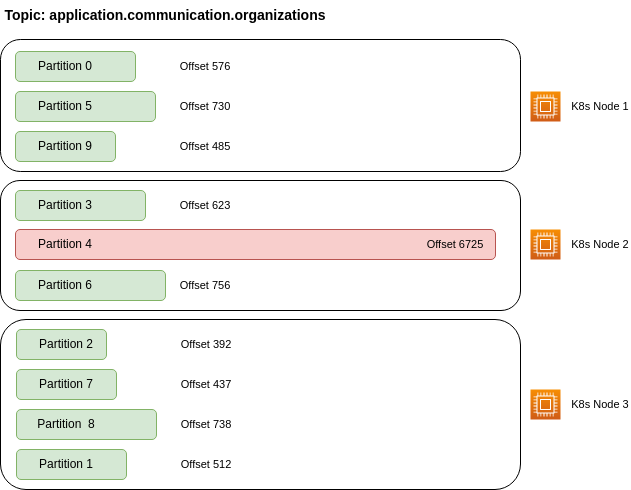
Learning 3: Unbalanced partitions
One more thing that we learned is that it is important to choose the correct keys for the data in Kafka. Since one Kafka broker is responsible for a particular topic-partition, having some keys that receive lots of data will lead to unbalanced partitions and unbalanced load distribution.
For example, if we key messages with organization_id and have some organizations that receive the majority of the data - this can cause performance problems on the broker side. As data for the same key will be written to the same topic-partition, some brokers will need to work very hard when writing and reading the data (for these organizations) and some will be idle. The microservices that need to consume a topic will also be blocked as they consume a topic from different partitions and the response time of the Kafka brokers under load will impact the overall responsiveness of the system.
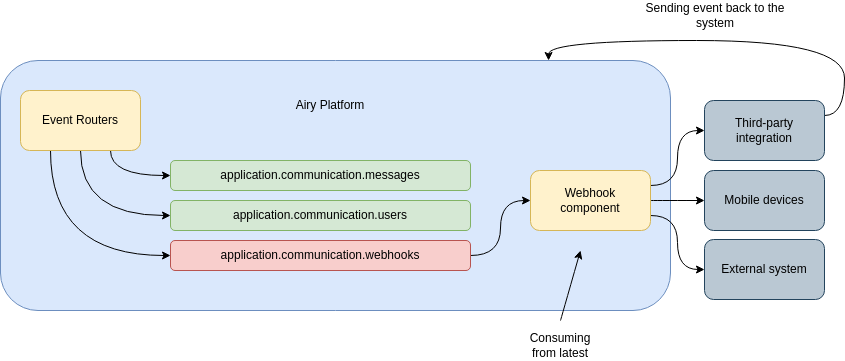
Learning 4: Webhook events
Our platform uses a webhook component to send events to external systems. As we cannot assume that these systems will be idempotent, these events must be sent only once. However, as the webhook events are read from topics inside Kafka, when there is an outage or during broker upgrades, information about the current offset of these topics can be lost. Even though the webhook component consumes from the latest messages in a topic, if there is an inconsistency in the offsets it can happen that a message is sent multiple times.
This problem can be particularly hard to debug and investigate as we would like to offload the responsibility to Kafka to keep the correct offset for every topic. What we can do to mitigate this problem and avoid such inconveniences, like triggering a CRM system with the same event multiple times, we can add some application logic to the webhook deployment and double-check that a certain event should be sent on the side of the webhook component.
Learning 5: Starting up all at once
Kafka Streams Apps require lots of CPU at startup. At first they go in a REBALANCING state to check the consistency of the data, either in the RocksDB cache or in the internal topics. Once the data is there and broker assignments are completed for looking for new data, these apps go into a RUNNING state and then the CPU usage reduces. At the same time there is a spike of the CPU usage in Kafka as the Kafka brokers need to respond to all of these requests from the apps getting ready to start. If we have hard limits on the total resources that the workloads can consume, when everything starts at once (for example during upgrades or when a pool of Kubernetes nodes die) we can have a problem that the workloads don’t get the needed CPU to get into a RUNNING state.
One way we managed to mitigate this behavior is using init containers in the Kubernetes workloads to look for conditions whether an app can start at all (for example if Kafka is still not ready). We can configure our CD pipeline not to upgrade all the components at the same time, but this will not affect the behavior when some nodes in Kubernetes get replaced and Kubernetes schedules all workloads on another node. In this case, creating (and testing) an auto-scaling configuration for the particular group of Kubernetes resources will be helpful as the workloads can get more resources when they need.
Learning 6: Backup
All the data is in one place, right? So in that sense - backup is easy. As long as we have a backup of Kafka - we are good. Unfortunately it is not so simple.
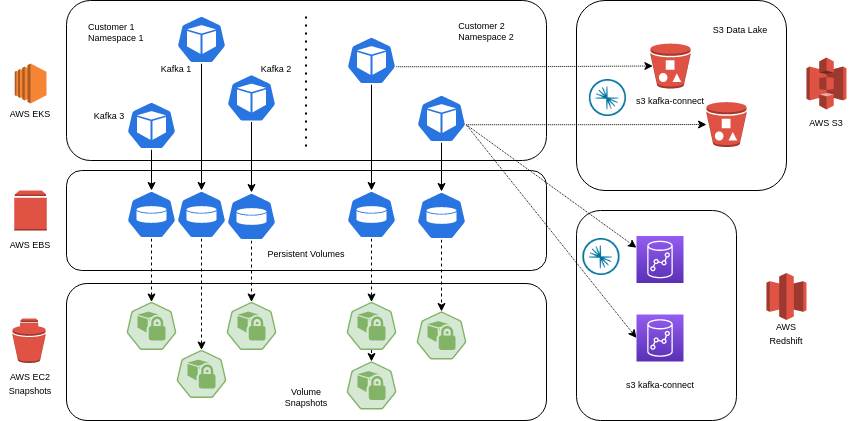
Let’s assume the most straightforward scenario where we have the data in Kafka in persistent volumes (for example EBS volumes in AWS). We need to make periodical snapshots of these volumes and that is the easy part. But restore is not so easy. If we need to restore the data to a certain point in time we need to: 1) Stop all the Brokers, 2) Restore all of the snapshots from the same backup cycle, 3) Start all the brokers at once, 4) Wait for them to rebalance and get in a running state.
This will restore all the data in Kafka to a certain point in time. But what if we want to restore only part of the data or only one topic? Then this solution doesn’t work anymore. If this is needed it would be best to make use of kafka-connect and stream all the topics independently to external storage. One example is the s3 sink connector that will write all the data in real-time to an S3 bucket. Note that not all connectors support the same ordering of the data, so if this is important you may want to choose a connector that can guarantee that.
Learning 7: Tools
Tooling is very important for maintaining every platform and Airy is not an exception. But as all of the data is in Kafka we need tools that can interact with Kafka and help us with:
- Checking the state of the broker
- Looking into the data in the topics
- Searching for a particular key/value in a topics
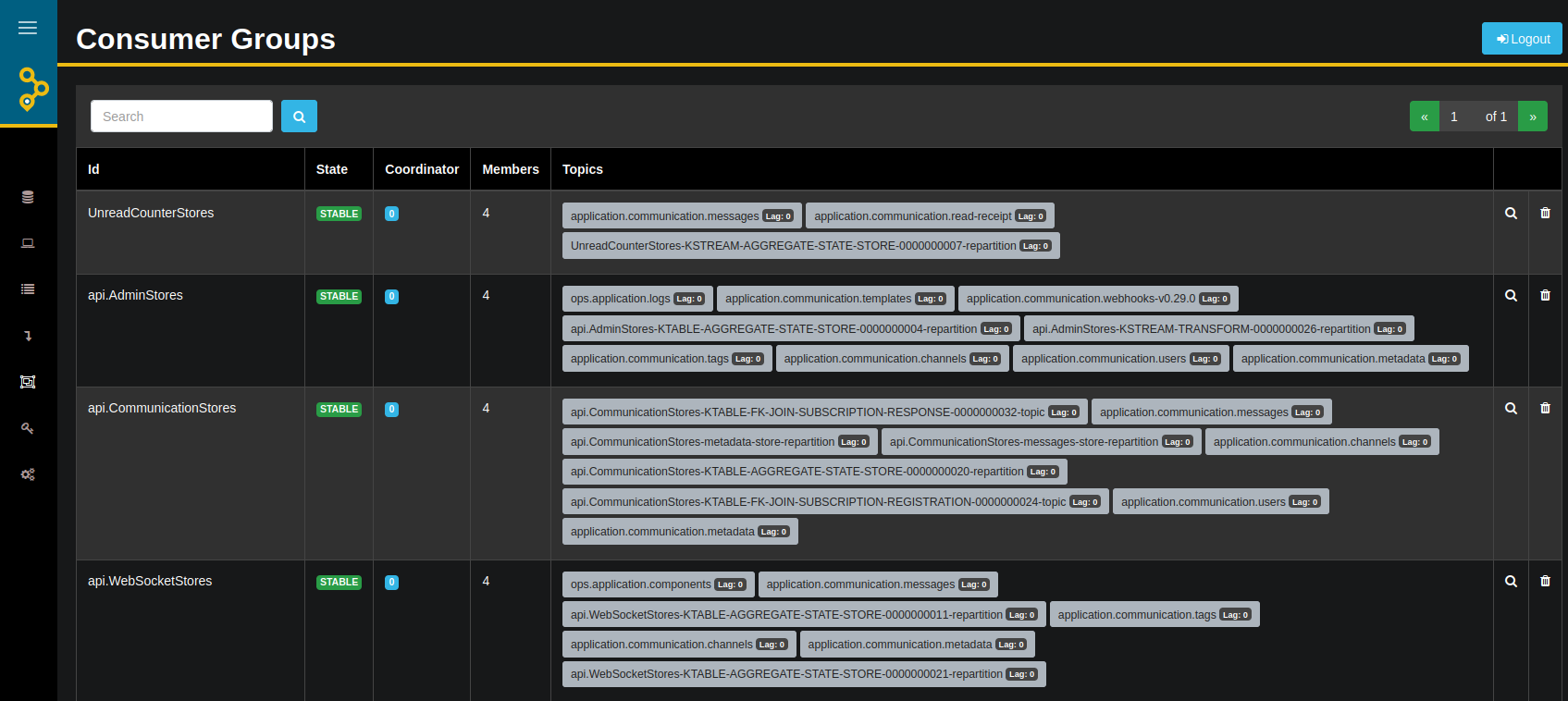
- Looking into the state of the consumer groups and check the lag
- Check the status of Kafka connect
- View the schema for a particular topic
- See the rate at which data is written/read to/from Kafka
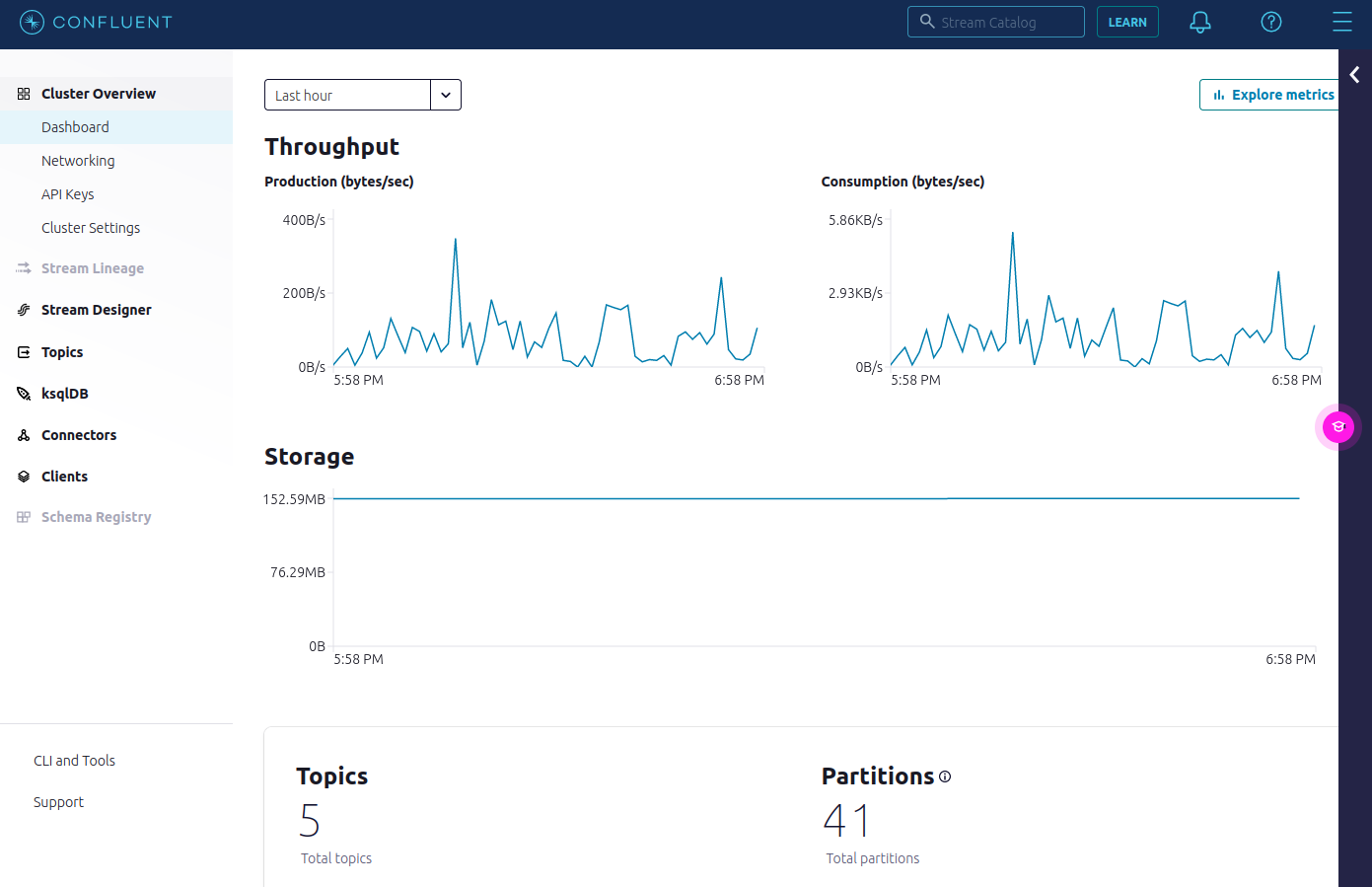
As a complete turn-key solution - Confluent cloud is very useful for getting a clear insight of the data in Kafka. Clusters can be created and destroyed easily with Terraform, as well as topics, access lists and service accounts. This works however only if you have the Kafka clusters in Confluent.
If you choose to run and manage your own Kafka then the first tool that everyone should have is AKHQ. It can be deployed easily with Helm in Kubernetes, needs access to the Kafka cluster and can offer great insight in the state of the data and the platform.
Apart from these great UIs there, kcat is a great CLI that can be used to interact with Kafka.
The Positive Leranings
Even though it was a bumpy ride and the learning curve is a bit steep, using Kafka as a single source of truth proved to be a great choice for our platform. We achieved an unified development process with great flexibility, speed and agility. All the data is in one place, so it is easy to govern, segment and use.
When the data is in Kafka one cannot just go there and change or delete a record in the database. It is a streaming platform and this forces you to solve data issues programmatically, not allowing shortcuts such as editing the database to fix a data problem. For example, when there is a Null Point Exception a new version of the microservice needs to be created solving the issue.
Another positive learning is that Kafka Streams actually solves lots of issues for distributed processing. Scaling consumers and producers is very convenient and Kafka distributes the workload automatically. When a consumer or a producer dies, all the information is stored in Kafka so they can just restart and continue where they left off. And Interactive queries are a great way to expose structured data in Kafka via HTTP.
Kubernetes has proven very convenient for running Kafka under low and moderate load, even though for higher Kafka loads we would recommend running a dedicated instance for every Kafka broker.
So making the stream the single source of truth is something that we can recommend. Most importantly all data can be accessed and processed in the same way and in real time, which is very important for building a robust event-driven platform.
Data Retention
When using Kafka as a central dataase the data retention question becomes important as usually we don't want to delete events from our single source of truth. But keeping all the data can lead to high disk usage and large volumes, so we need to decide which data is important to keep and which is not.
Fortunately Kafka has a great feature for this called data compaction. We can actually decide that we keep at least the latest value for an unique key that gets written to a topic, instead of deleting it.
Here is a snippet of our scripts for creating the topics:
kafka-topics.sh --create --if-not-exists "${CONNECTION_OPTS[@]}" --replication-factor "${REPLICAS}" --partitions "${PARTITIONS}" --topic "${AIRY_CORE_NAMESPACE}application.communication.contacts" --config cleanup.policy=compact min.compaction.lag.ms=86400000 segment.bytes=10485760
kafka-topics.sh --create --if-not-exists "${CONNECTION_OPTS[@]}" --replication-factor "${REPLICAS}" --partitions "${PARTITIONS}" --topic "${AIRY_CORE_NAMESPACE}application.communication.messages" --config cleanup.policy=compact min.compaction.lag.ms=86400000 segment.bytes=10485760
kafka-topics.sh --create --if-not-exists "${CONNECTION_OPTS[@]}" --replication-factor "${REPLICAS}" --partitions "${PARTITIONS}" --topic "${AIRY_CORE_NAMESPACE}application.communication.metadata" --config cleanup.policy=compact min.compaction.lag.ms=86400000 segment.bytes=10485760
When it comes down to compaction it is important that all the conditions are created so that compaction kicks in. The data stored in the topic-partitions is stored in segments that are individual files written to the disk. The last segment is the one that Kafka writes to in real-time so compaction is done only from the messages in the previous segments. Having that in mind it is important that we configure the size of the segment in accordance to the amount of messages that that topic is receiving. Because if there is only one large segment - none of the messages will actually be compacted and will still be kept on disk.
It is important to say that campacting the messages removes historical data so we need to be sure that we are good with that. For example we have messages that we key with a messageId. If we compact that topic, then we for sure keep the value or the content of the last message, but historical information about previous versions of the message will be lost.
References
[1] Airy Core Open source repository - https://github.com/airyhq/airy/
[2] Airy design principles - https://airy.co/docs/core/concepts/design-principles
[3] Apache Kafka - https://kafka.apache.org/
[4] Kafka Streams - https://kafka.apache.org/documentation/streams/
[5] Confluent Cloud - https://www.confluent.io/confluent-cloud/
[6] AKHQ - https://akhq.io/
[7] Backup of EBS volumes on AWS - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSSnapshots.html